
If you’ve read my previous post, you already know about the birth of the idea for DAX Optimizer and the very first steps we took, like registering the daxoptimizer.com domain. But there’s a lot more to the story. Today, I’d like to delve deeper into the research phase, the blood, sweat, and code that went into turning this idea into reality.
The beginnings
One of the primary challenges that needed tackling was the development of two crucial technological components: a DAX parser and an agent to extract statistical information.
I had already developed a basic parser for DAX Formatter, but we had a tough decision on whether to enhance this existing component or start anew. That analysis required more time. However, for the statistical information extraction, we had no existing tool, and this became my first research priority.
The creation of VertiPaq Analyzer
I recall the first time I rolled up my sleeves to create the first version of VertiPaq Analyzer. It happened during one of my countless travels, and today it’s a critical part of our infrastructure. VertiPaq Analyzer extracts statistical information from a Tabular model: the first release was implemented as a Power Pivot model in Excel.
Fast-forward a few years, and the upgraded VertiPaq Analyzer v2 saw me release a series of open-source .NET libraries to support the VPAX format, which is now a de-facto standard to collect and transfer statistical information about a Tabular model deployed to Power BI or Analysis Services. These libraries are now utilized by multiple tools, including DAX Studio, Tabular Editor, and Bravo for Power BI.
Waiting on Microsoft, Tabular Editor steps up
There was a phase when we were optimistic that Microsoft might release a DAX parser, which could serve as the backbone of our tool. Sadly, that didn’t materialize. During this time, I came across Daniel Otykier, the genius behind the first version of Tabular Editor. Our shared need for a parser led to a multitude of discussions until Daniel committed to a multi-year journey of creating a full DAX parser capable of truly “understanding” DAX beyond just validating syntax.
With the goal of creating a sustainable economic model for the development, this project led to the creation of Tabular Editor 3, arguably the best and most productive DAX development environment for Power BI and Analysis Services Tabular.
The birth of the DAX Optimizer core engine
The DAX parser in Tabular Editor enriched its features and became the solid foundation for the core engine of DAX Optimizer. This engine diligently analyzes the structure and dependencies of all DAX measures within a model.
Daniel and I went through numerous iterations, analyzing all DAX functions and creating an estimated cost for every code part. We operated without a strict deadline, working purely on research and development until we could convincingly show that the static analysis of the code could identify the main bottlenecks in both simple and complex models without running any report.
Eventually, we reached a point where we convinced ourselves that the system worked. Though it was still limited in handling all functions and use cases, we knew we were onto something big. The next logical step was to devise a business plan, secure development funding, and assemble the team to define the user interface and implement the entire infrastructure we have today.
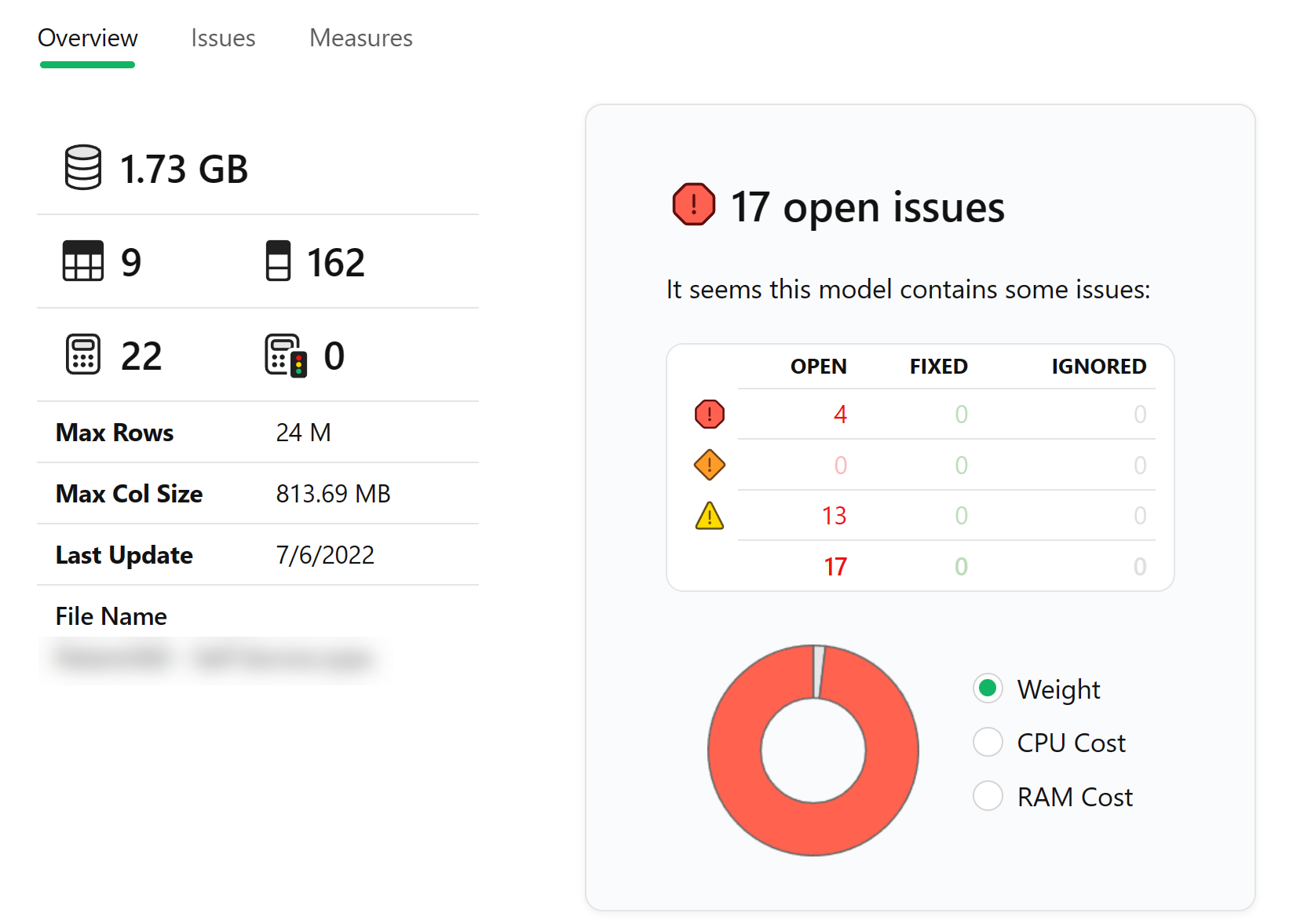
Wrapping up
As a final takeaway, I’d like to share a critical lesson from this journey. Quality research takes time and shouldn’t be rushed by strict deadlines. We had to make crucial decisions regarding refactoring the code or changing our approach in core parts of the engine – decisions that would not have been sustainable in a more advanced stage of development. But the freedom of exploration and the luxury of time led us to where we are today: DAX Optimizer started its beta test with real users and is no longer a laboratory experiment.
Our story continues, and we look forward to sharing more in our upcoming posts. Stay tuned for more!